Event Streaming platform
- 고성능 데이터 파이프라인 구축에 활용된다
- 처음에는 간단한 서비스는 단방향 통신으로 충분하지만
- 서비스의 양이 늘어나면 간단한 기능을 위한 파이브라인이 매우 복잡해짐
- 서비스가 세분화되고 나눠지면서 이 서비스들 사이의 정보 교환을 어떻게 할것인가? (Http로 할수 있으나 거미줄처럼 됨)

Apache Kafka 등장
발생하는 모든 사건들을 Kafka에 전달
- 사건들에 대해 알아야 하는 서비스가 해당 정보를 구독하고 서비스를 제공한다.
- Event Driven Architecture (사건이 발생하면 프로세스가 진행됨, 즉 이벤트가 트리거)
개별 서비스의 결합력이 줄어든다.(카프카만 구독하면 되니까)
-> 독립적으로 발전할수 있다.
RabbitMQ vs Kafka?
성능의 차이가 있을 뿐이다?
- RabbitMQ: 메시지의 보관 보다는 전달에 초첨을 맞춘 Message Broker
- Kafka: 대량의 사건(Event)의 흐름(Stream)을 관리하고 보관 (메시지 관리에 초점)
RabbitMQ는 애플리케이션 간의 비동기 통신에 초점 -> 기능적 측면의 개발에서 유용
Kafka는 고가용성의 이벤트 저장소 -> 많은 데이터를 안정적으로 관리하는데 유용(RabbitMQ 상위호환)
Topic
Kafka에 전달딘 메시지를 분류하는 단위
- 말그대로 주제
- 데이터베이스의 테이블, 파일시스템의 폴더 같이
Topic - Partition
Topic 내부에서 실제로 데이터가 순차적으로 쌓이는 곳
- 순서를 가지고 저장된다 (Offset)
- Partition의 데이터는 읽어도 사라지지 않는다 (RabbitMQ랑 가장 큰 차이점)
Partition을 늘릴수는 있지만, 줄일수는 없다
- 영속성을 나타내는 데이터이기 때문에 Partition을 삭제하는것은 데이터를 삭제하는 행위이다.

Consumer Group
Consumer의 갯수만큼 Partition에서 동시에 데이터를 가져온다
- 이때 여러 Consumer를 Group으로 묶으면 하나의 데이터를 Group의 하나의 Consumer만 읽는다 (병렬 처리 가능)

Broker
Kafka가 설치된 서버
- 여러개의 kafka Broker를 구성해 Cluster를 만들면, 한 서버에 문제가 생겨도 대처할수 있다.

Broker - Replicaiton
Broker가 여럿일때, Replicaiton Factor를 정의
- 여러개의 Broker를 거쳐 Topic의 Partition이 복제된다.
- 실제로 메세지를 받는 Leader와 Leadewr의 데이터를 복제하는 Follower로 구성
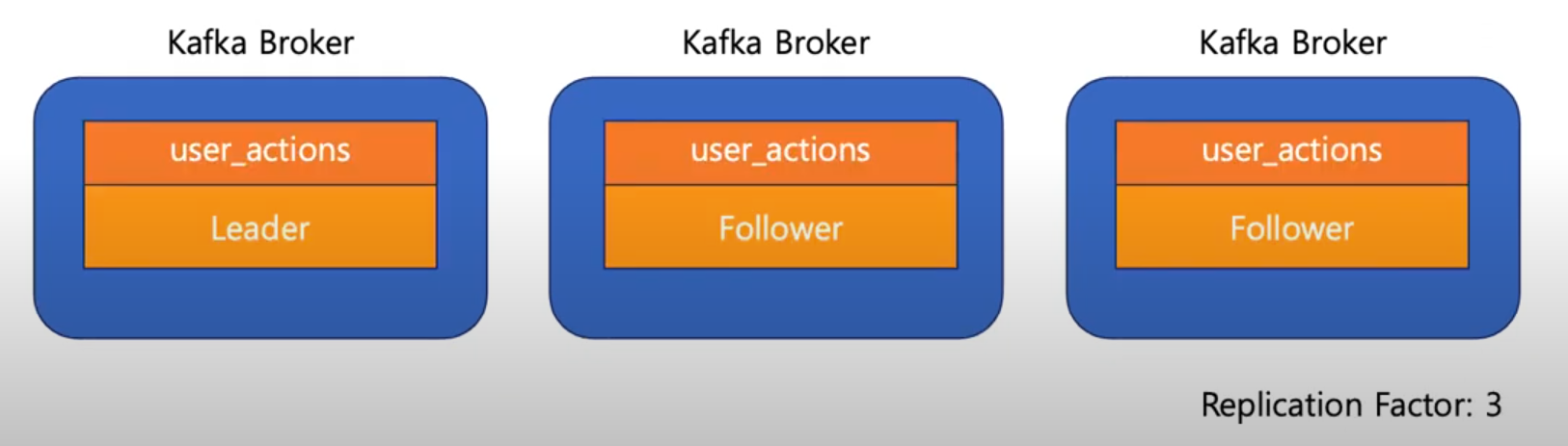
Leader에 문제가 생기면 다른 Broker에서 Leader의 역할을 이어받는다.
- 이후 Broker가 다시 돌아오면 Leader로부터 손실된 데이터 복구 가능(새로운 Follower가 된다)

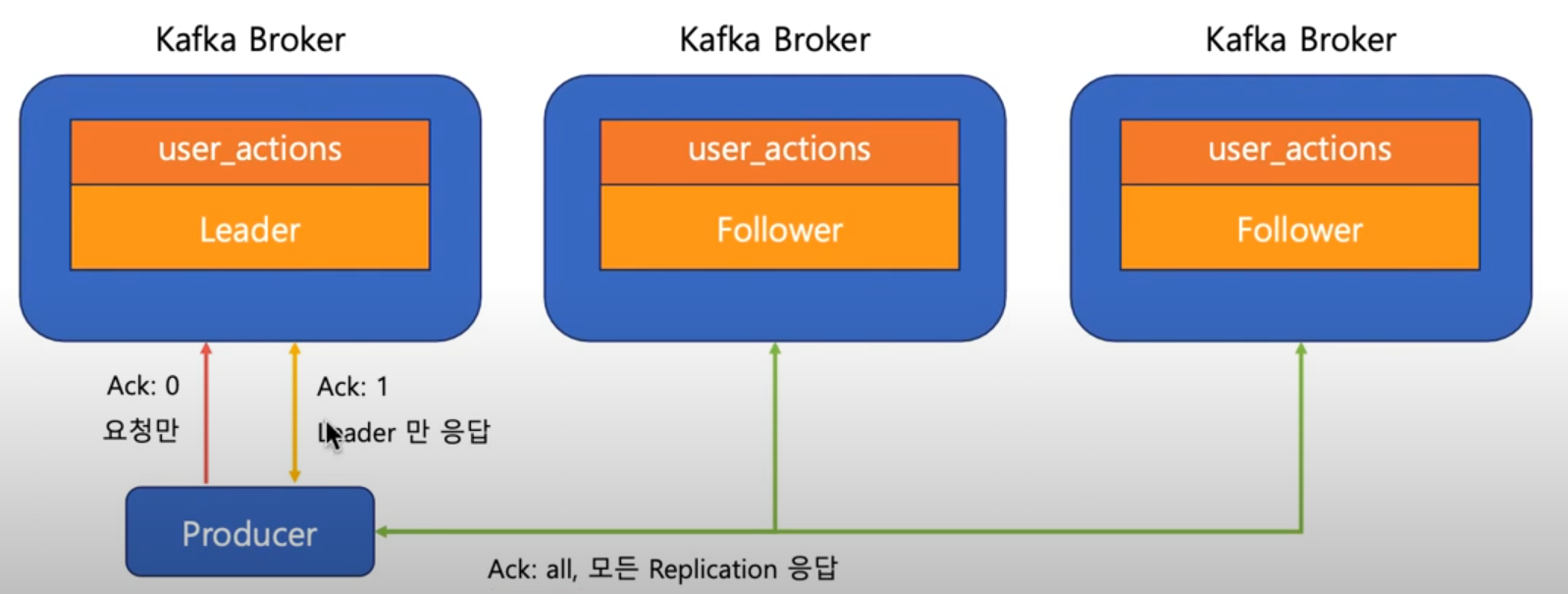
Ack
Producer가 데이터를 전달할때, Replication에 데이터가 저장됐는지 확인하는 설정
- Ack: 0 , 요청만 보냄(안전성은 낮지만 속도가 빠름)
- Ack: 1, 요청을 보내고 리더만 응답(안전성 보통이고 속도 보통)
- Ack: all, 요청을 보내면 모든 Replication이 응답(안전성 높고 속도 느림)
카프카 실행하기
카프카 설치
https://kafka.apache.org/downloads
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
주키퍼 먼저 실행 (브로커들을 관리)
/kafka$ ./bin/zookeeper-server-start.sh config/zookeeper.properties
카프카 실행
/kafka$ ./bin/kafka-server-start.sh ./config/server.properties
이때 /tmp 에 로그가 생성되니 초기화 하려면 /tmp의 카프카 로그들과 주키퍼를 초기화해야함 (여기서 부터 읽고 시작하기 때문)
토픽 생성
/kafka$ ./bin/kafka-topics.sh --create --topic first-topic --bootstrap-server localhost:9092
토픽 확인
/kafka$ ./bin/kafka-topics.sh --describe --topic first-topic --bootstrap-server localhost:9092
프로듀서 생성
/kafka$ ./bin/kafka-console-producer.sh --topic first-topic --bootstrap-server localhost:9092
컨슈머 생성
/kafka$ ./bin/kafka-console-consumer.sh --topic first-topic --from-beginning --bootstrap-server localhost:9092
이렇게하면 프로듀서에서 생성한 메서지를 바로 컨슈머에서 확인 가능하다.