이번 포스팅에서는 kmeans 알고리즘을 직접 구현해보는것 위주로 리뷰하겠습니다.
kmeans는 임의로 중심을 정하는 부분과 모든 데이터에 대해서 중심 거리를 각각 구해서 가장 거리가 작은 중심으로 그룹핑하고 또 각각의 그룹마다 다시 평균을 구하고 반복하는데 평균이 변화가 거의없이 수렴하면 종료합니다.
자세한 사항은 위키백과를 참고해주세요.
https://ko.wikipedia.org/wiki/K-%ED%8F%89%EA%B7%A0_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
k-평균 알고리즘 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. k-평균 알고리즘(K-means clustering algorithm)은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작
ko.wikipedia.org
이런 흐름으로 코드와 주석을 함께보시면 이해하실것 같습니다.
Code
import cv2
import numpy as np
import math
from matplotlib import pyplot as plt
import random
def kmeans(data, k):
t = np.copy(data)
cen = []
for i in range(k):
c = np.hstack((np.random.randint(0, data.shape[0], size=1), np.random.randint(0, data.shape[1], size=1)))
cen.append(data[c[0]][c[1]]) # randomly selection of centroid
print(cen)
while True:
label_list = []
for i in range(k):
l = []
label_list.append(l) # it's like [[], [], ... , [], []] double list to contain each label
for i in range(data.shape[0]):
for j in range(data.shape[1]):
l1 = []
for z in range(k):
l1.append(dist(data[i][j], cen[z])) # distance with centroid
n = l1.index(min(l1)) # to find min, n means a index to which the value belongs
label_list[n].append(data[i][j]) # stack the value which belongs to that index
t[i][j] = cen[n] # mapping copy image t to centroid value to plot at the last result
temp = np.copy(cen)
cen = [] # now to update centroid
for w in range(k):
cen.append( np.mean(label_list[w], axis=0)) # perform column mean to each label so that we get new centroid
sum = 0
for i in range(k):
sum += dist(temp[i], cen[i]) # end condition
print(sum)
if sum / k < 1:
break
print(cen)
return t # to plot the image after k_mean
imageFile = '../pepper.bmp'
img1 = cv2.imread(imageFile, cv2.IMREAD_COLOR)
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img1 = cv2.resize(img1,dsize=(256, 256))
t = kmeans(img1, 7)
plt.subplot(1,2,1)
plt.imshow(img1, vmin=0, vmax=255)
plt.subplot(1,2,2)
plt.imshow(t, vmin=0, vmax=255)
plt.show()
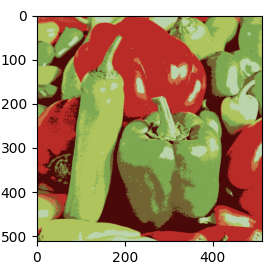
아래는 원본과 비교한 결과영상입니다. 색상의 개수(K=7)별로 클러스터링된것을 확인할수 있습니다.
Result
 |
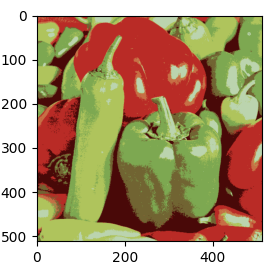 |
| 원본 | 직접 구현한 kmeans(K=7) |
 |
 |
| 원본 | 직접 구현한 kmeans(K=7) |
아래 코드는 opencv 라이브러리를 이용한 코드입니다. 위에서 얻은 결과와 비교해보겠습니다.
Code
import cv2
import numpy as np
from matplotlib import pyplot as plt
src = cv2.imread('../house.bmp', cv2.IMREAD_COLOR)
src = cv2.cvtColor(src, cv2.COLOR_BGR2RGB)
data = src.reshape((-1, 3)).astype(np.float32)
# K-means 알고리즘
# 최대 100번 반복하거나 1픽셀 이하로 움직이면 종료
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 1.0)
K = 7
print('K:', K)
# label은 각각의 데이터가 속한 군집 정보, center은 군집의 중심점 좌표
ret, label, center = cv2.kmeans(data, K, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
# 군집화 결과를 이용하여 출력 영상 생성
center = np.uint8(center)
# 중심점 좌표를 받아서 dst에 입력 (262144, 3) 3은 중심 좌표
dst = center[label.flatten()] # 각 픽셀을 K개 군집 중심 색상으로 치환
# 입력 영상과 동일한 형태로 변환 (512,512,3)
dst = dst.reshape((src.shape))
plt.subplot(1,2,1)
plt.imshow(src, vmin=0, vmax=255)
plt.subplot(1,2,2)
plt.imshow(dst, vmin=0, vmax=255)
plt.show()
Result
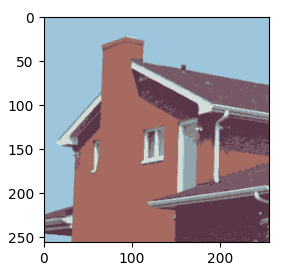
 |
 |
| 직접 구현한 kmeans(K=7) | opencv kmean(K=7) |
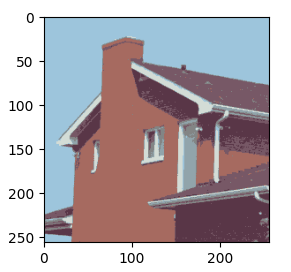 |
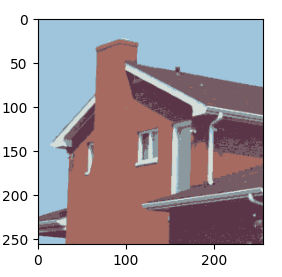 |
| 직접 구현한 kmeans(K=7) | opencv kmean(K=7) |
분석
라이브러리와 거의 차이가 나지않는 수준으로 구현에 성공하였습니다. 하지만 opencv에서는 1초안에 결과물이 나온 반면 직접 구현한 kmean는 이미지 크기가 (512,512)일때 1분 정도 걸렸습니다. 아마 opencv는 알고리즘에서 Brute Force 알고리즘대신 좀더 빠르게 그룹핑을 할수있는 알고리즘을 채택한것 같습니다.
감사합니다.
'컴퓨터 비전 > 실습' 카테고리의 다른 글
| prewitt, sobel, canny 구현(python) (0) | 2023.02.10 |
|---|---|
| mean shift 직접 구현하기(python) (0) | 2023.01.31 |
| SIFT 직접 구현하기(python) (0) | 2023.01.25 |
| Bilateral Filter 직접 구현하기(python) (0) | 2023.01.18 |



